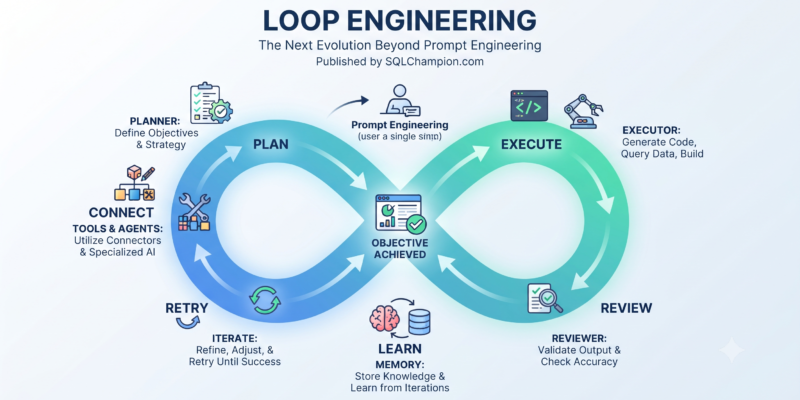
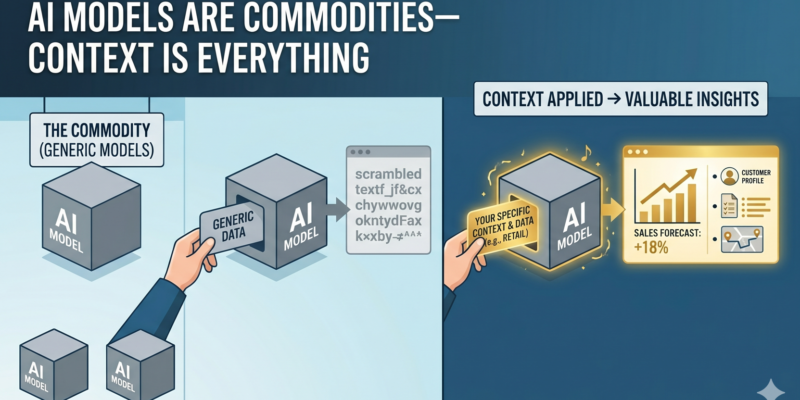
If you’ve been following what I write about agents and MCP, you know I’m a little obsessed with the shift from “AI that talks” to “AI that acts.” Chatbots answer. Agents do. OpenCode is one of the clearest examples of that shift I’ve come across lately, and it’s open source — which, if you know me, is basically a guaranteed way to get my attention. So let’s break it down: what it actually is, why I think it matters, and where it fits next to tools like Claude Code and Cursor. What Is OpenCode, Really? OpenCode is an open-source AI… Read more