Microsoft Fabric is an all-in-one analytics platform designed for organizations that covers everything from data storage and data movement to data science and real-time analytics.
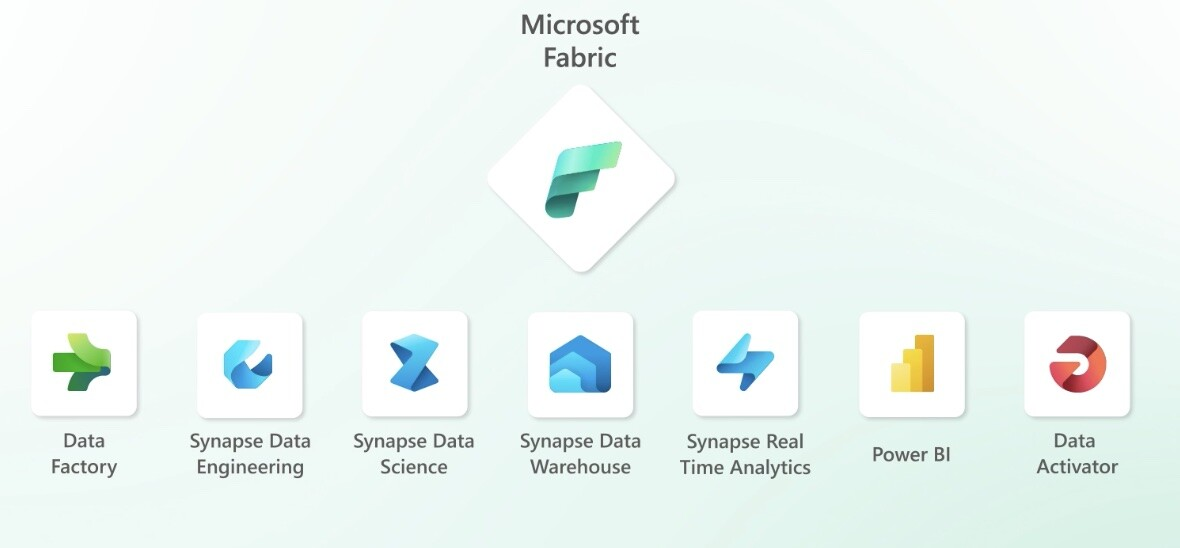
It’s a unified platform that brings together a diverse range of technologies and tools into a single solution. It offers a comprehensive suite of services, including data lake, data engineering, and data integration, all in one place.
Components of Microsoft Fabric
As part of the Microsoft Fabric trial, users can access six exciting services. One component called Data Activator is currently still in private preview but will likely become available soon, so keep an eye out for updates!
Now let’s go over the six services you can access via Fabric.
1. Data Factory
Data Factory brings together the best of Azure Data Factory and Microsoft Power Query.
It enables organizations to seamlessly access a variety of data estates and unlock value with a data integration experience that combines the ease of use of Power Query with the scale and power of Data Factory.
In Microsoft Fabric, Data Factory empowers you with:
- Data pipelines directly in Fabric: The service comes with a rich set of integration capabilities, enabling you to begin any copy task from data sources to data destinations.
- Extensive connectivity: It supports connectivity to more than 170+ data stores, including cloud databases, on-premises data sources, analytical platforms, and more.
- Built-in artificial intelligence: Like other tools in the Microsoft 365 suite, Data Factory also comes with AI that can help you accelerate and automate common tasks.
- Next-gen Power BI dataflows: You can access more than 300 data transformations right out of the box, including AI transformations and scalable data flows.
Data Factory offers a low code but customizable experience for creating a powerful and comprehensive data solution as the amount of data that organizations need to process continues to grow ever larger, there’s no denying the importance of data engineering.
2. Synapse Data Engineering
Synapse Data Engineering is one of the core products offered by Fabric. It empowers data professionals to collaborate on their projects, ranging from data warehousing, data integration, business intelligence, and data science.
Some of its key experiences include:
- Robust Lakehouse architecture: Synapse Data Engineering brings the best of data lake and data warehouse, reducing the friction of ingesting, transforming, and sharing data. It can also be used to leverage the power of Apache Spark to transform data at scale and build out a robust Lakehouse architecture.
- Runtime 1.1. to give users a great default performance: Synapse Data Engineering ships with Runtime 1.1, which includes Python 3.10, Apache Spark 3.3.1, and Delta 2.2. Spark Runtime is pre-wired to every workspace by default, so no tuning is required.
- Notebooks for a superior developer experience: Synapse Data Engineering features notebooks that support a variety of tools, programming languages, and libraries. Notebooks have native Lakehouse integration, co-authoring, and integration with Spark, VS Code, and more.
These are just a few of the features that are currently available in Synapse Data Engineering. Microsoft plans to release a wide variety of capabilities over the coming months, including copilot integration, enhanced Lakehouse security, environments, and more.
3. Synapse Data Warehouse
Synapse Data Warehouse brings next-gen data warehousing capabilities to Microsoft Fabric. It natively supports an open data format so data engineers, IT teams, and business users can seamlessly collaborate without compromising enterprise security.
Some of its improvements over the previous data warehouse generation include:
- Fully managed: Synapse Data Warehouse is a fully managed SaaS solution with features to support those with no coding skills and developers who love to write code.
- Open data standards: Data is not locked behind the proprietary SQL Server format. Synapse Data Warehouse uses an open data standard and supports interoperability with the Spark ecosystem.
- Cross-querying: Thanks to the open data standard support, data in the warehouse can be queried and cross-joined in Fabric or any other computer engine.
- Automatic scaling: The data warehouse can automatically scale its resources as usage requirements go up and scales down when those resources aren’t needed anymore, all without user intervention.
All of this and more can be accessed from the Fabric homepage for Data Warehouse. All you need to do to get started is a name and a sensitivity label. No additional setup is required!
4. Synapse Data Science
Synapse Data Science enables data scientists to work on top of the same secured data that has been prepared by data engineering teams without having to copy data or figure out ways to gain secure access.
Additionally, users can gain access to a variety of experiences, including machine-learning tools, low-code tools, and collaborative code authoring through Notebooks and Visual Studio Code.
Some of the core experiences offered by Synapse Data Science include:
- Data Wrangler: Data Wrangler is a powerful tool for all your data preparation needs. It makes cleaning and preparing data easier than ever before with seamless integration with Python libraries like Pandas. Future updates will include support for natural language processing via Azure OpenAI and Spark.
- Access to ML tools: Synapse Data Science has built-in ML tools and supports MLFlow and the Synapse ML library. Depending on your settings, your data team can use it to run experiments with machine learning models and capture key metrics to further train models and gain insights from data.
- R language support: In addition to supporting code authoring with Python, Data Science also has native support for the R language on Apache Spark.
5. Synapse Real-Time Analytics
Synapse Real-Time Analytics makes data integration simple for large organizations and enables quick access to data insights through automatic data streaming, indexing, and partitioning and auto-generated visualizations and queries.
Real-Time Analytics can ingest data in any format and from any source without the need of complex scripts or data models to transform data. It has unlimited scalability (from terabytes to petabytes) for concurrent users and queries, making it the perfect solution for organizations that work with high-volume, high-speed data streams.
The best part? It’s seamlessly integrated with all of Fabric’s components, including Power BI, Lakehouse, and Data Warehouse.
Some other features of Synapse Real-Time Analytics include:
- Instant Power BI report generation: You can create reports for your data with just one click.
- Use of only one logical copy: Your data is stored in Microsoft OneLake and directly integrated into other Fabric components.
- Real-time streaming and complex data structure transformation: It can begin querying data within seconds of ingestion
Synapse Real-Time Analytics offers a variety of data analytics services and simplifies integration with other Microsoft Fabric services.
Its ability to ingest and query data from any source for data analysis as well as scale to handle large volumes of data makes it an ideal service for organizations that want to stay on top in a data-driven world.
6. OneLake
OneLake is what Microsoft is calling the “OneDrive for data.” It’s a multi-cloud data lake where you can store all your organizational data, just like how you can use OneDrive for your documents.
It provides you with:
- One data estate that can scale with your organization’s needs
- One data copy for use across numerous analytical engines available in Fabric (T-SQL, Spark, etc.)
- One universal security model so you only have to define security definitions once that are enforced across all analytical engines
OneLake is basically a centralized Microsoft data platform for managing data with your team. Collaboration is baked in and one Fabric tenant automatically gains exactly one OneLake instance where all of your organization’s data is stored — no additional setup is necessary!
Some core features of OneLake include:
- Unified management and governance: Through OneLake workspaces, different teams can work independently using the same data lake. Each workspace can have its own admin and access control.
- Data mesh and domains: OneLake lets teams organize data logically and efficiently by enabling different business groups to operate and manage their own data. For instance, you could use data mesh to define a variety of business domains, such as sales, human resources, marketing, ecommerce, and more. Each domain will contain its respective data (engagement and site statistics, personalized content and ads, etc.), enabling optimized consumption and more granular control for admins.
- Open at every level: OneLake is built on Azure Data Lake Storage Gen2 and can support any file type. All of Fabric’s components like Power BI, lakehouses, and warehouses will automatically store their data in OneLake.
- File Explorer for Windows: You can access OneLake directly from Windows using the OneLake file explorer app. This app integrates OneLake and Data Lake for Fabric right into your Windows File Explorer, simplifying data warehousing and making data accessible even to non-technical users.